14 KiB
RapidJSON Tutorial
This tutorial introduces the basics of the Document Object Model(DOM) API.
As shown in Usage at a glance, a JSON text can be parsed into DOM, and then the DOM can be queried and modfied easily, and finally be converted back to JSON text.
Value & Document
Each JSON value is stored in a type called Value. A Document, representing the DOM, contains the root of Value.
Querying Value
In this section, we will use excerpt of example/tutorial/tutorial.cpp.
Assumes we have a JSON text stored in a C string (const char* json):
{
"hello": "world",
"t": true ,
"f": false,
"n": null,
"i": 123,
"pi": 3.1416,
"a": [1, 2, 3, 4]
}
Parse it into a Document
#include "rapidjson/document.h"
using namespace rapidjson;
// ...
Document document;
document.Parse(json);
The JSON text is now parsed into document as a DOM tree:
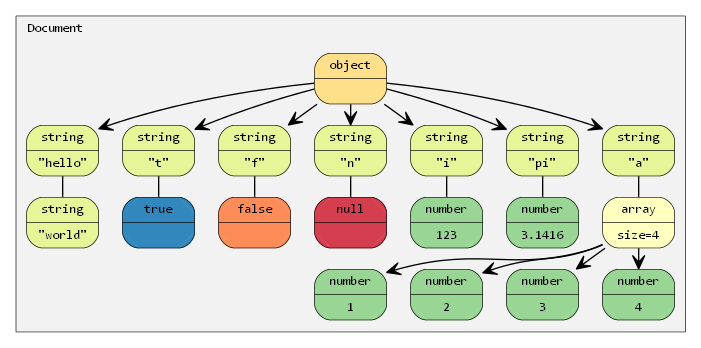
The root of a conforming JSON should be either an object or an array. In this case, the root is an object.
assert(document.IsObject());
Query whether a "hello" member exists in the root object. Since a Value can contain different types of value, we may need to verify its type and use suitable API to obtain the value. In this example, "hello" member associates with a JSON string.
assert(document.HasMember("hello"));
assert(document["hello"].IsString());
printf("hello = %s\n", document["hello"].GetString());
world
JSON true/false values are represented as bool.
assert(document["t"].IsBool());
printf("t = %s\n", document["t"].GetBool() ? "true" : "false");
true
JSON null can be queryed by IsNull().
printf("n = %s\n", document["n"].IsNull() ? "null" : "?");
null
JSON number type represents all numeric values. However, C++ needs more specific type for manipulation.
assert(document["i"].IsNumber());
// In this case, IsUint()/IsInt64()/IsUInt64() also return true.
assert(document["i"].IsInt());
printf("i = %d\n", document["i"].GetInt());
// Alternative (int)document["i"]
assert(document["pi"].IsNumber());
assert(document["pi"].IsDouble());
printf("pi = %g\n", document["pi"].GetDouble());
i = 123
pi = 3.1416
JSON array contains a number of elements.
// Using a reference for consecutive access is handy and faster.
const Value& a = document["a"];
assert(a.IsArray());
for (SizeType i = 0; i < a.Size(); i++) // Uses SizeType instead of size_t
printf("a[%d] = %d\n", i, a[i].GetInt());
a[0] = 1
a[1] = 2
a[2] = 3
a[3] = 4
Note that, RapidJSON does not automatically convert values between JSON types. If a value is a string, it is invalid to call GetInt(), for example. In debug mode it will fail an assertion. In release mode, the behavior is undefined.
In the following, details about querying individual types are discussed.
Querying Array
By default, SizeType is typedef of unsigned. In most systems, array is limited to store up to 2^32-1 elements.
You may access the elements in array by integer literal, for example, a[1], a[2]. However, a[0] will generate a compiler error. It is because two overloaded operators operator[](SizeType) and operator[](const char*) is avaliable, and C++ can treat 0 as a null pointer. Workarounds:
a[SizeType(0)]a[0u]
Array is similar to std::vector, instead of using indices, you may also use iterator to access all the elements.
for (Value::ConstValueIterator itr = a.Begin(); itr != a.End(); ++itr)
printf("%d ", itr->GetInt());
And other familar query functions:
SizeType Capacity() constbool Empty() const
Quering Object
Similarly, we can iterate object members by iterator:
static const char* kTypeNames[] =
{ "Null", "False", "True", "Object", "Array", "String", "Number" };
for (Value::ConstMemberIterator itr = document.MemberBegin();
itr != document.MemberEnd(); ++itr)
{
printf("Type of member %s is %s\n",
itr->name.GetString(), kTypeNames[itr->value.GetType()]);
}
Type of member hello is String
Type of member t is True
Type of member f is False
Type of member n is Null
Type of member i is Number
Type of member pi is Number
Type of member a is Array
Note that, when operator[](const char*) cannot find the member, it will fail an assertion.
If we are unsure whether a member exists, we need to call HasMember() before calling operator[](const char*). However, this incurs two lookup. A better way is to call FindMember(), which can check the existence of member and obtain its value at once:
Value::ConstMemberIterator itr = document.FindMember("hello");
if (itr != 0)
printf("%s %s\n", itr->value.GetString());
Querying Number
JSON provide a single numerical type called Number. Number can be integer or real numbers. RFC 4627 says the range of Number is specified by parser.
As C++ provides several integer and floating point number types, the DOM tries to handle these with widest possible range and good performance.
When the DOM parses a Number, it stores it as either one of the following type:
| Type | Description |
|---|---|
unsigned |
32-bit unsigned integer |
int |
32-bit signed integer |
uint64_t |
64-bit unsigned integer |
int64_t |
64-bit signed integer |
double |
64-bit double precision floating point |
When querying a number, you can check whether the number can be obtained as target type:
| Checking | Obtaining |
|---|---|
bool IsNumber() |
N/A |
bool IsUint() |
unsigned GetUint() |
bool IsInt() |
int GetInt() |
bool IsUint64() |
uint64_t GetUint() |
bool IsInt64() |
int64_t GetInt64() |
bool IsDouble() |
double GetDouble() |
Note that, an integer value may be obtained in various ways without conversion. For example, A value x containing 123 will make x.IsInt() == x.IsUint() == x.IsInt64() == x.IsUint64() == ture. But a value y containing -3000000000 will only makes x.IsInt64() == true.
When obtaining the numeric values, GetDouble() will convert internal integer representation to a double. Note that, int and uint can be safely convert to double, but int64_t and uint64_t may lose precision (since mantissa of double is only 52-bits).
Querying String
In addition to GetString(), the Value class also contains GetStringLength(). Here explains why.
According to RFC 4627, JSON strings can contain unicode character U+0000, which must be escaped as "\u0000". The problem is that, C/C++ often uses null-terminated string, which treats ``\0'` as the terminator symbol.
To conform RFC 4627, RapidJSON supports string containing U+0000. If you need to handle this, you can use GetStringLength() API to obtain the correct length of string.
For example, after parsing a the following JSON string to Document d.
{ "s" : "a\u0000b" }
The correct length of the value "a\u0000b" is 3. But strlen() returns 1.
GetStringLength() can also improve performance, as user may often need to call strlen() for allocating buffer.
Besides, std::string also support a constructor:
string( const char* s, size_type count);
which accepts the length of string as parameter. This constructor supports storing null character within the string, and should also provide better performance.
Create/Modify Values
There are several ways to create values. After a DOM tree is created and/or modified, it can be saved as JSON again using Writer.
Changing Value Type
When creating a Value or Document by default constructor, its type is Null. To change its type, call SetXXX() or assignment operator, for example:
Document d; // Null
d.SetObject();
Value v; // Null
v.SetInt(10);
v = 10; // Shortcut, same as above
Overloaded Constructors
There are also overloaded constructors for several types:
Value b(true); // calls Value(bool)
Value i(-123); // calls Value(int)
Value u(123u); // calls Value(unsigned)
Value d(1.5); // calls Value(double)
To create empty object or array, you may use SetObject()/SetArray() after default constructor, or using the Value(Type) in one shot:
Value o(kObjectType);
Value a(kArrayType);
Move Semantics
A very special decision during design of RapidJSON is that, assignment of value does not copy the source value to destination value. Instead, the value from source is moved to the destination. For example,
Value a(123);
Value b(456);
b = a; // a becomes a Null value, b becomes number 123.

Why? What is the advantage of this semantics?
The simple answer is performance. For fixed size JSON types (Number, True, False, Null), copying them is fast and easy. However, For variable size JSON types (String, Array, Object), copying them will incur a lot of overheads. And these overheads are often unnoticed. Especially when we need to create temporary object, copy it to another variable, and then destruct it.
For example, if normal copy semantics is used
Value o(kObjectType);
{
Value contacts(kArrayType);
// adding elements to contacts array.
// ...
o.AddMember("contacts", contacts); // deep clone contacts (may be with lots of allocations)
// destruct contacts.
}
The object o needs to allocate a same size buffer as contacts, makes a deep clone of it, and then finally contacts is destructed. This will incur a lot of unnecessary allocations/deallocations.
There are solutions to prevent actual copying these data, such as reference counting and garbage collection(GC).
To make rapidjson simple and fast, we chose to use move semantics for assignment. It is similar to auto_ptr<> which transfer ownership during assignment. Move is much faster and simpler, it just destructs the original value, memcpy() the source to destination, and finally sets the source as Null type.
So, with move semantics, the above example become:
Value o(kObjectType);
{
Value contacts(kArrayType);
// adding elements to contacts array.
o.AddMember("contacts", contacts); // just memcpy() of contacts itself to the value of new member (16 bytes)
// contacts became Null here. Its destruction is trivial.
}
This is called move assignment operator in C++11. As RapidJSON supports C++03, it adopts move semantics as default.
Manipulating String
RapidJSON provide two strategies for storing string.
- copy-string: allocates a buffer, and then copy the source data into it.
- const-string: simply store a pointer of string.
Copy-string is always safe because it owns a copy of the data. Const-string can be used for storing string literal, and in-situ parsing which we will mentioned in Document.
To make memory allocation customizable, rapidjson needs user to pass an instance of allocator, whenever that operation may require allocation. This design is more flexible than STL's allocator type per class, as we can assign a allocator instance for each allocation.
Therefore, when we assign a copy-string, we call this overloaded SetString() with allocator:
Document document;
Value author;
char buffer[10];
int len = sprintf(buffer, "%s %s", "Milo", "Yip"); // dynamically created string.
author.SetString(buffer, len, document.GetAllocator());
memset(buffer, 0, sizeof(buffer));
// author.GetString() still contains "Milo Yip" after buffer is destroyed
In this example, we get the allocator from a Document instance. This is a common idiom when using rapidjson. But you may use other instances of allocator.
Besides, the above SetString() requires the length of a string. This can handle null characters within a string. There is another SetString() overloaded function without the length parameter. And it actually assumes the input is null-terminated and calls a strlen()-like function to obtain the length.
Finally, for literal string or string with safe life-cycle can use const-string version of SetString(), which are without alloactor parameter:
Value s;
s.SetString("rapidjson", 9); // faster, can contain null character
s.SetString("rapidjson"); // slower, assumes null-terminated
s = "rapidjson"; // shortcut, same as above
Manipulating Array
Value with array type provides similar APIs as std::vector.
Clear()Reserve(SizeType, Allocator&)Value& PushBack(Value&, Allocator&)template <typename T> GenericValue& PushBack(T, Allocator&)Value& PopBack()
Note that, Reserve(...) and PushBack(...) may allocate memory, therefore requires an allocator.
Here is an example of PushBack():
Value a(kArrayType);
Document::AllocatorType& allocator = document.GetAllocator();
for (int i = 5; i <= 10; i++)
a.PushBack(i, allocator); // allocator is needed for potentially realloc.
// Fluent interface
a.PushBack("Lua", allocator).PushBack("Mio", allocator);
Differs from STL, PushBack()/PopBack() returns the array reference itself. This is called fluent interface.
Manipulating Object
Object is a collection of key-value pairs. Each key must be a string value. The way to manipulating object is to add/remove members:
Value& AddMember(Value&, Value&, Allocator& allocator)Value& AddMember(const Ch*, Allocator&, GenericValue& value, Allocator&)Value& AddMember(const Ch*, Value&, Allocator&)template <typename T> Value& AddMember(const Ch*, T value, Allocator&)bool RemoveMember(const Ch*)
There are 4 overloaded version of AddMember(). They are 4 combinations for supplying the name string (copy- or const-), whether to supply a different allocator for name string, and whether use generic type for value.
Here is an example.
Value contact(kObejct);
contact.AddMember("name", "Milo", document.GetAllocator());
contact.AddMember("married", true, document.GetAllocator());